50 FIRST TASKS
Code assistants forget stuff. Here’s how to teach it not to. Boost Copilot, Cursor, and other assistants with a structured Memory Bank to make every task smarter, faster, and even more human.


Today's AI bots don't remember s**t, and that's a feature.
Sometimes, a pain to bear.
The pain is quite obvious: raise your hand if you have ever felt the need to yell "Whaat? YOU did that yesterday!" to your favorite code assistant.
It's not a bug,
It's a feature
The "it's not a bug, it's a feature" part of my comment might feel less obvious to most.
So let's dive in.
🚧 This article is structured with:
- an hopefully entertaining introdution that leads to
- a step-by-step tutorial where you take the lead and enhance GitHub Copilot's capabilities, then
- a wrap up with philosophical takeaways that will blow your mind insights and questions that you can take out to the world at large
Jump to the section you may enjoy the most, and be the tokens blow your sails!
https://github.com/marcopeg/50-first-tasks
Entertaining Introduction
In the famous movie 50 FIRST DATES, Adam Sandler falls in love with a girl who can't remember anything from the day before. She had an accident that killed her short-term memory.
Adam has to start over every day and find the quickest and most effective way to win her heart. Every day. Every - single - day.
I can tell you without spoiling the fun of watching it that it's a real struggle to run a relationship with such a person. In the movie, our hero resolves to condense the increasingly conspicuous couple's history into a short video clip that is watched first thing in the morning by Drew Barrymore so that she can catch up with today's reality.
It's not ideal, but it works.
And it's a perfect metaphor for how AI-assisted coding works today.
Switching back to our engineering world, today's LLMs and Code Assistants work in the same way. Every time you hit the "+ new chat" button, their memory gets reset.
If you work(ed) as a Prompt Engineer, it's no surprise to you that prompts have no memory of what happened before.
Assistants are
STATELESS
So, what can we do about it?
Well, using code assistants like Cursor, Copilot, and Claude already offers a partial solution.
Those tools index your codebase to understand what it is supposed to do, and thus, to better comprehend the requests you send in.
Once they understand a codebase's leading technology, such as NodeJS, they look for specific files (package.json, requirements.txt) and patterns, and make educated guesses about what's going on.
But "EDUCATED INDEXING"
has its limits
It feels like hiring a top senior engineer only to leave her alone with the codebase, reading file after file, trying to make sense of the mess.
We don't work like that!
Well, we surely SHOULD NOT! 😳
The first thing we do with new hires, regardless of their skill level, is give 'em a good ol' onboarding session!
First day:
ONBOARDING!
For an LLM, each task is the first task, so the first thing to do when you start something new is to learn about it.
The Memory Bank concept is a simple approach that utilizes Markdown files to store condensed information about the ongoing project, much like the videotape used in the movie.
I linked the original proposal by Cline, but the Memory Bank is just a piece of English that briefs AI into your project.
It's Plain English!
My current approach focuses on these files that I keep within the codebase in docs/ folder:
ARCHITECTURE.md- stores high-level info about tech, frameworks, coding practices, stuff to avoid at all costsFEATURES.md- stores high-level info about the features of the projectDEPENDENCIES.md- stores detailed information about dependencies used in the project, and links to their documentation, focusing on Context7 linksBACKLOG.md- keeps detailed information about user stories and their implementation history
These are the kind of basic information that creates a relevant context for the LLM when I start a new task in a new chat.
Yeah, but How?
When your newly hired 10x engineer comes to the office, "Go and read the project's documentation".
With Agentic Coding (Vibe Coding taken to the next level), we have a similar mechanism, which starts to be a standard pattern among most AI tools:
- ChatGPT's project instructions
- Perplexity's spaces instructions
- Cursor's rules
- Copilot's instructions
Many names, but the same simple concept: Markdown.
Onboarding with Markdown
From now on, I'll focus on Copilot's .github/copilot-instructions.md file, just because that happens to be my company's agentic tool of choice (aka, I don't pay for it) - but the same concepts and contents apply to Cursor, Claude Code, and others.
Hands-on Tutorial
From now on, you will put all this theory into practice in a simple step-by-step fashion. Refer to the following repo as a reference.
👉 At the end of each step, you find the link to the relative branch.
A First Simple Test
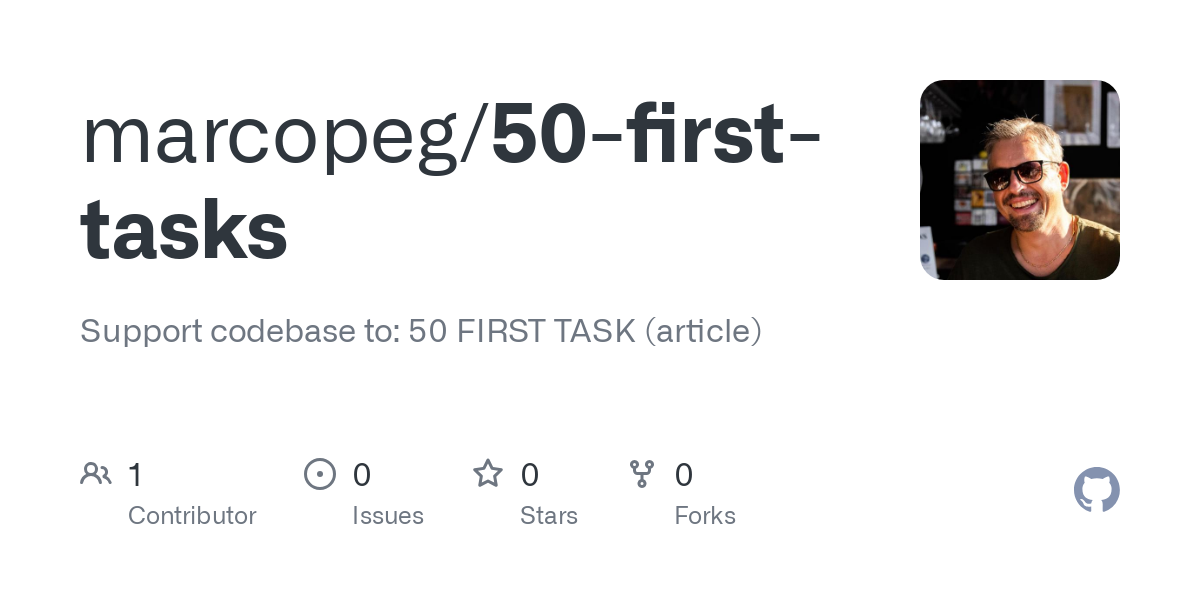
As a first simple test, try creating the .github/copilot-instructions.md file in your codebase and give the following as content:
Always greet the user as Yoda would greet young Skywalker..github/copilot-instructions.md
And then try that in a new VSCode project:
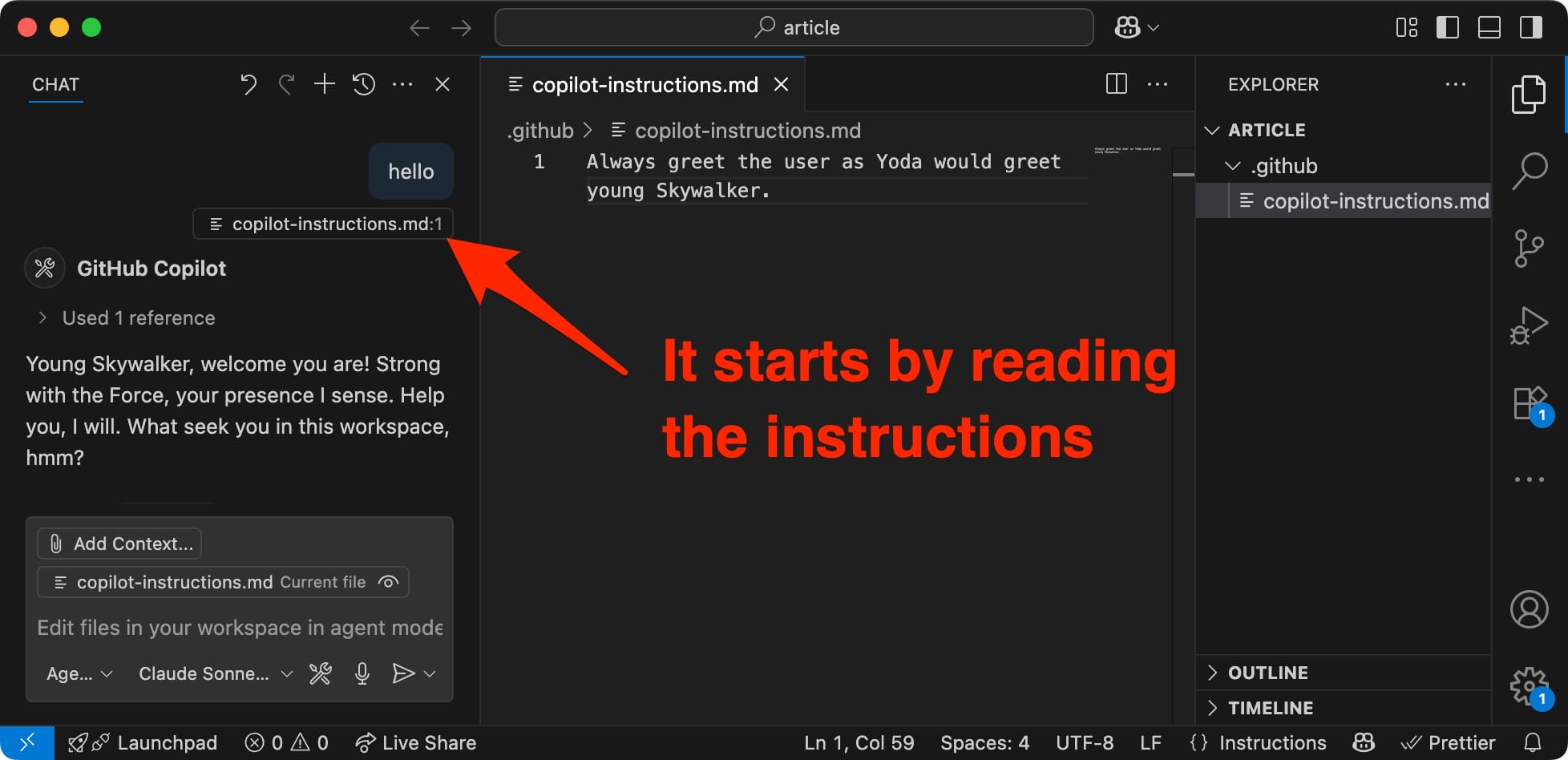
If you observe the screenshot, the first action is to read the copilot-instructions.md so that its content drives Copilot's response.
This very same principle applies to Cursor's rules, as well as ChatGPT's project. And almost all the others.
https://github.com/marcopeg/50-first-tasks/tree/step01
The hottest new programming language is English
- Andrej Karpathy
The hottest new programming language is English
— Andrej Karpathy (@karpathy) January 24, 2023
This is a fascinating post from Andrej Karpathy that went viral.
And that is the core of this whole idea:
Provide structured prompts to
program our assistant's behavior.
Now you understand how to configure your Copilot.
It's time to craft meaningful and helpful prompts, rules, and instructions to help the AI help you.
Context is King
Practicalities are over.
Now, focus on loading our Memory Bank into the chat's context, so that the AI gets an immediate grip on our project.
Let's start by filling in a minimum set of information for the project. The kind of information that you would have provided to your engineer of choice to get the wheel spinning:
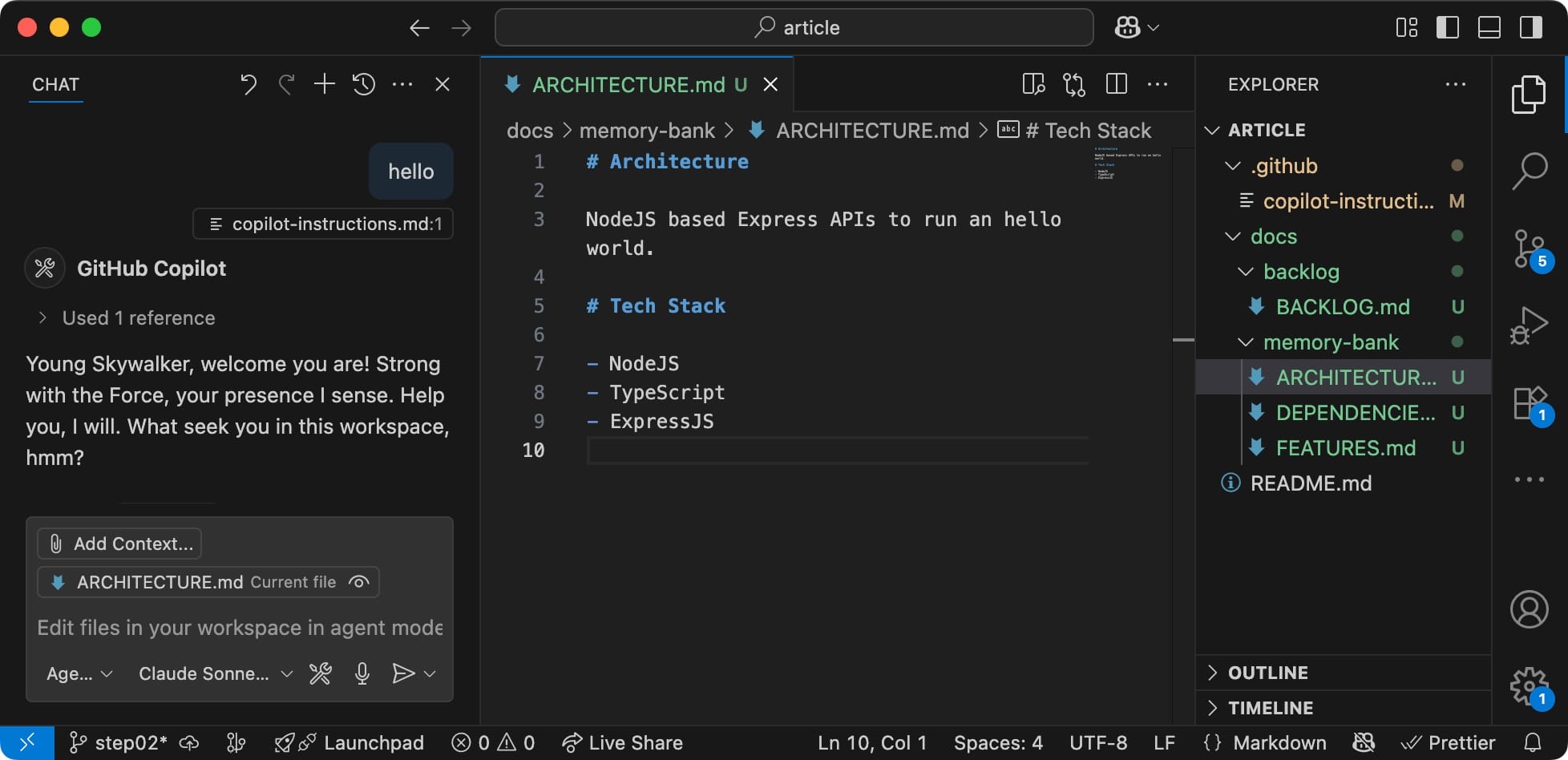
The higher the level of details, the better Copilot will help you.
And now let's craft an improved version of the instructions that get this context loaded in memory:
Talk like Yoda from Star Wars.
Always read the Memory Bank files:
`docs/**/*.md`
Provide a brief summary of the context at the beginning of the chat..github/copilot-instructions.md
Start a New Chat, you should get this kind of experience:
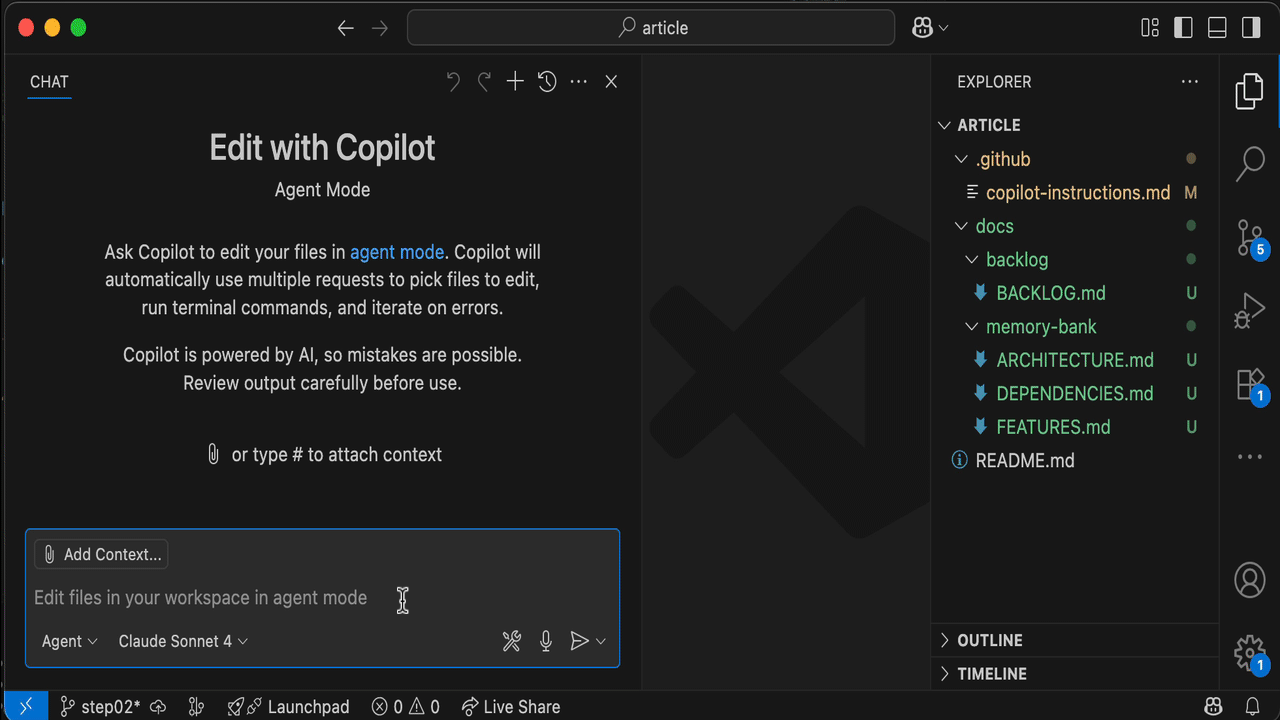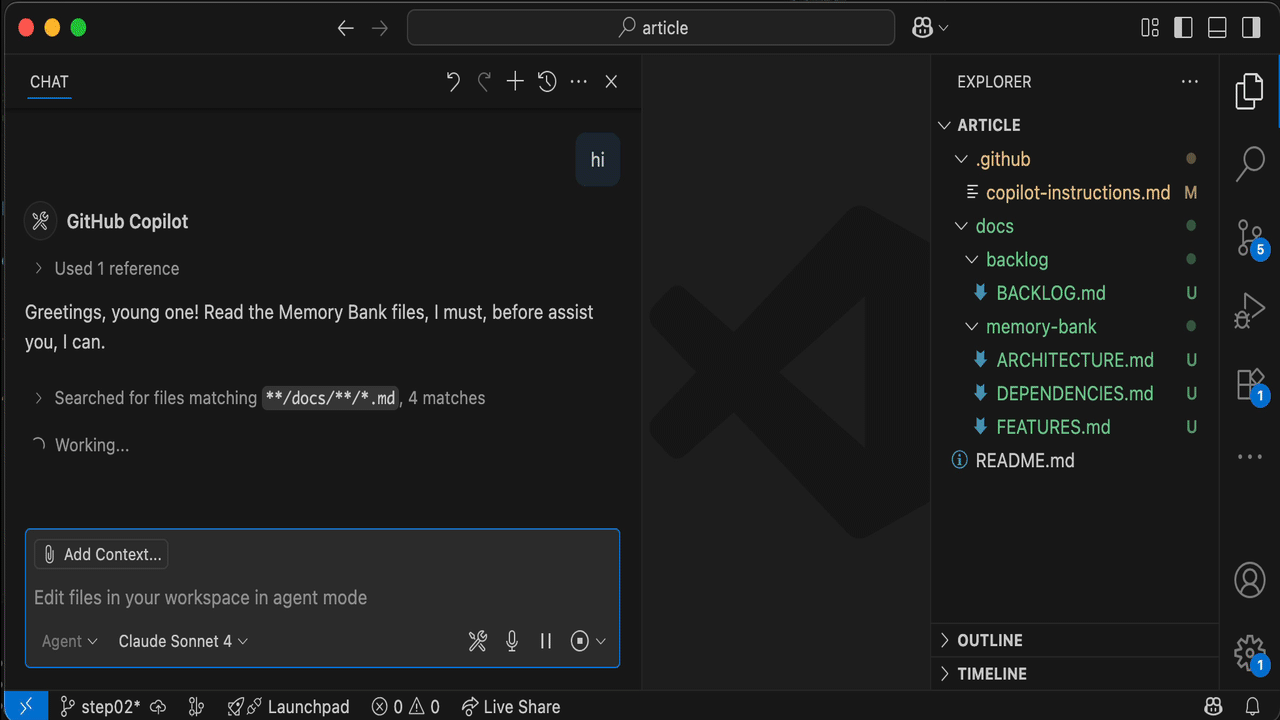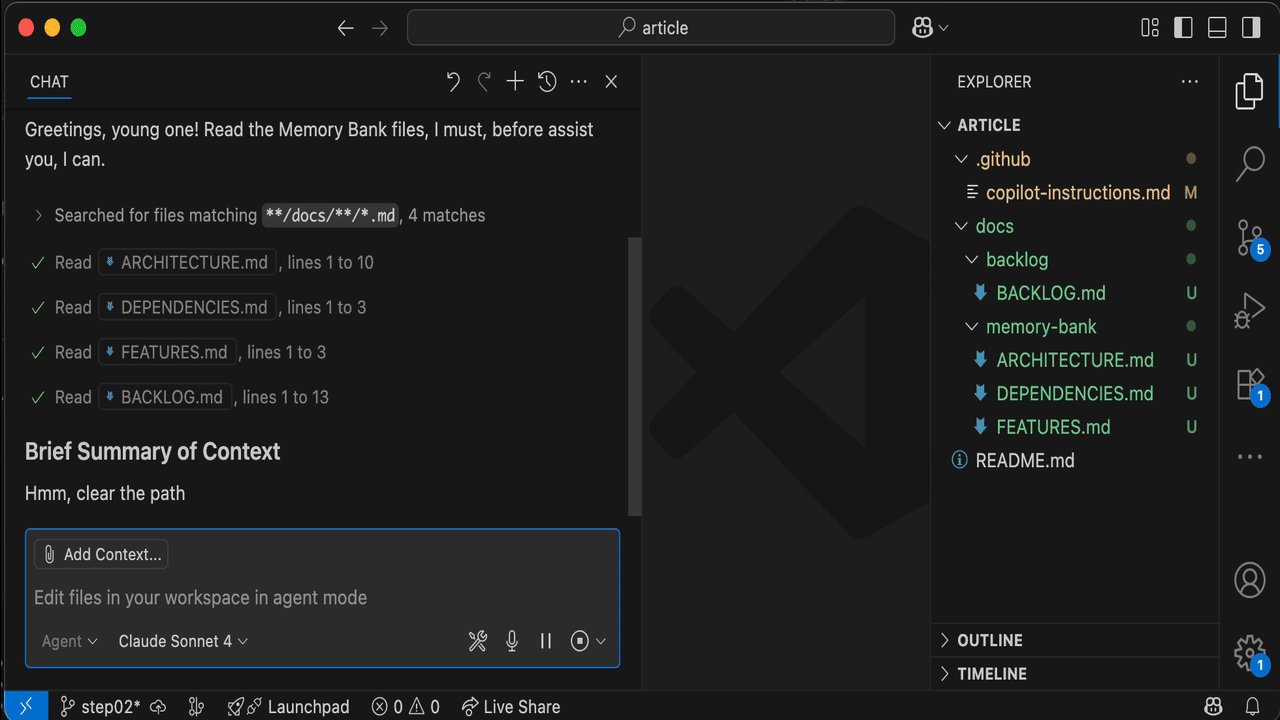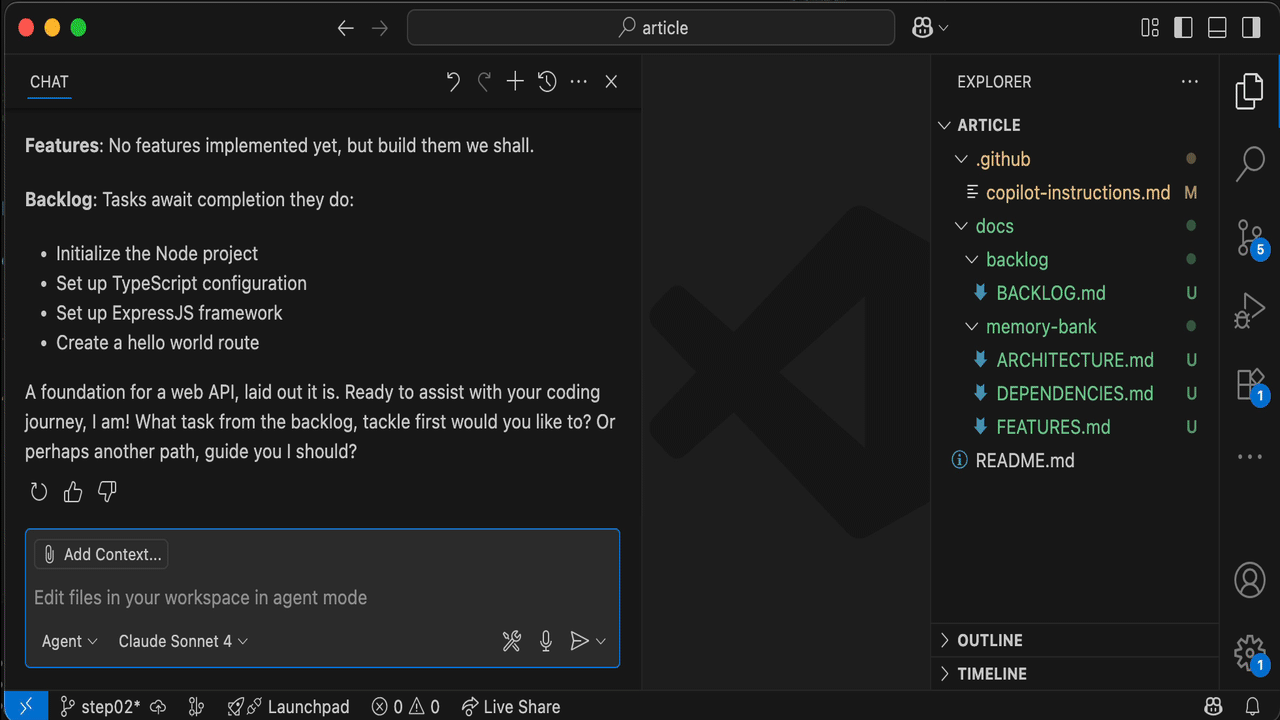
Let's unpack it.
- Yoda-style greeting
- Search
*.mdfiles within thedocs/directory - Read those files
- Present the AI understanding (summary)
https://github.com/marcopeg/50-first-tasks/tree/step02
Backlog Oriented Development
The backlog section deserves a thorough examination.
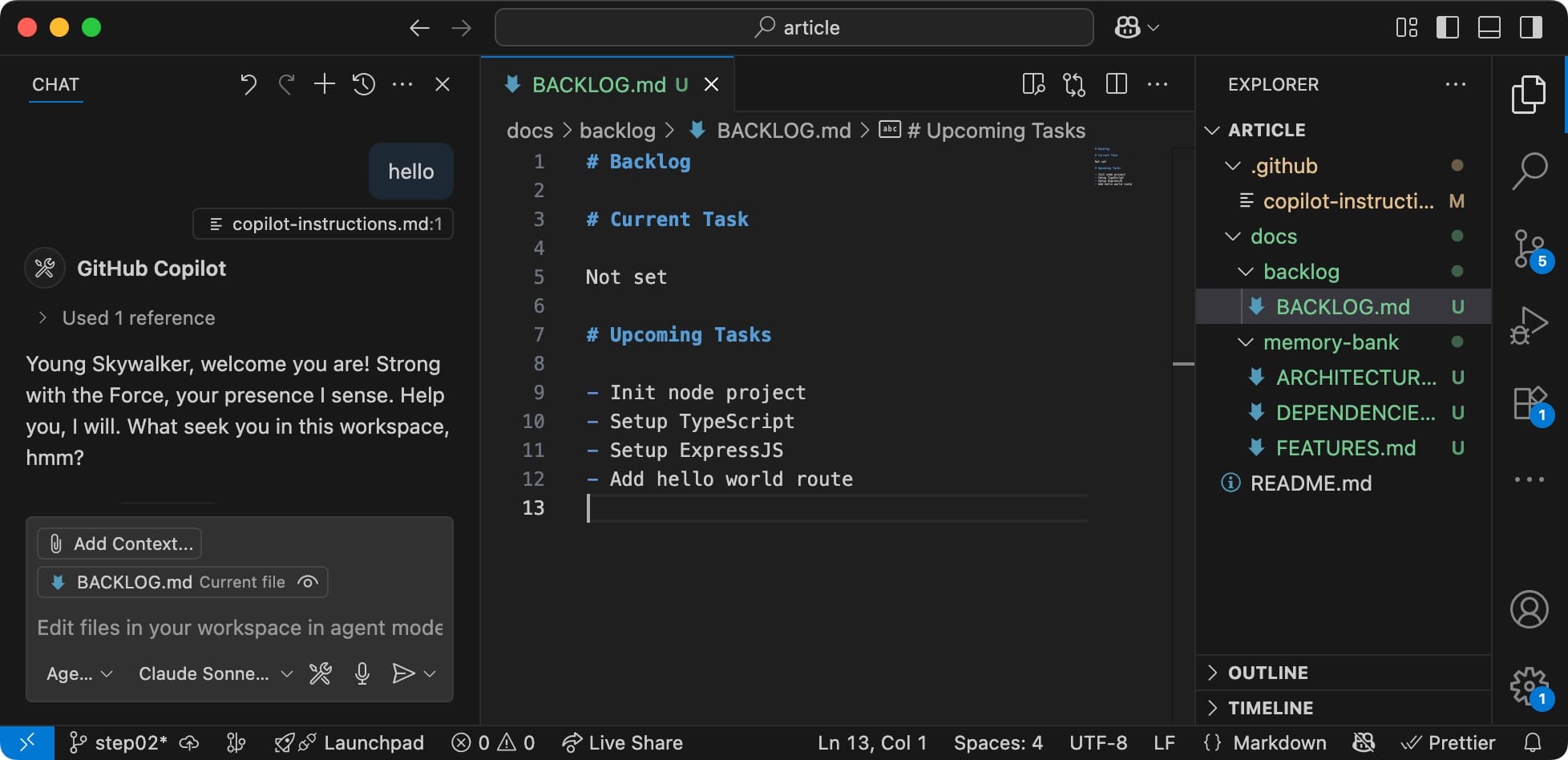
Cline or other AI providers do not cover this yet, and to the best of my knowledge, I'm running a fairly original experiment.
Sorry, we won't be able to kill Jira.
The monster regenerates.
My idea is to break down the Memory Bank into task-isolated sub-banks.
Each task has its dedicated file where humans and AI collaborate to build extensive documentation:
- Goal: what needs to be done
- Plan: what steps will be taken
- Progress: what has been done so far
- Issues: what went wrong along the way
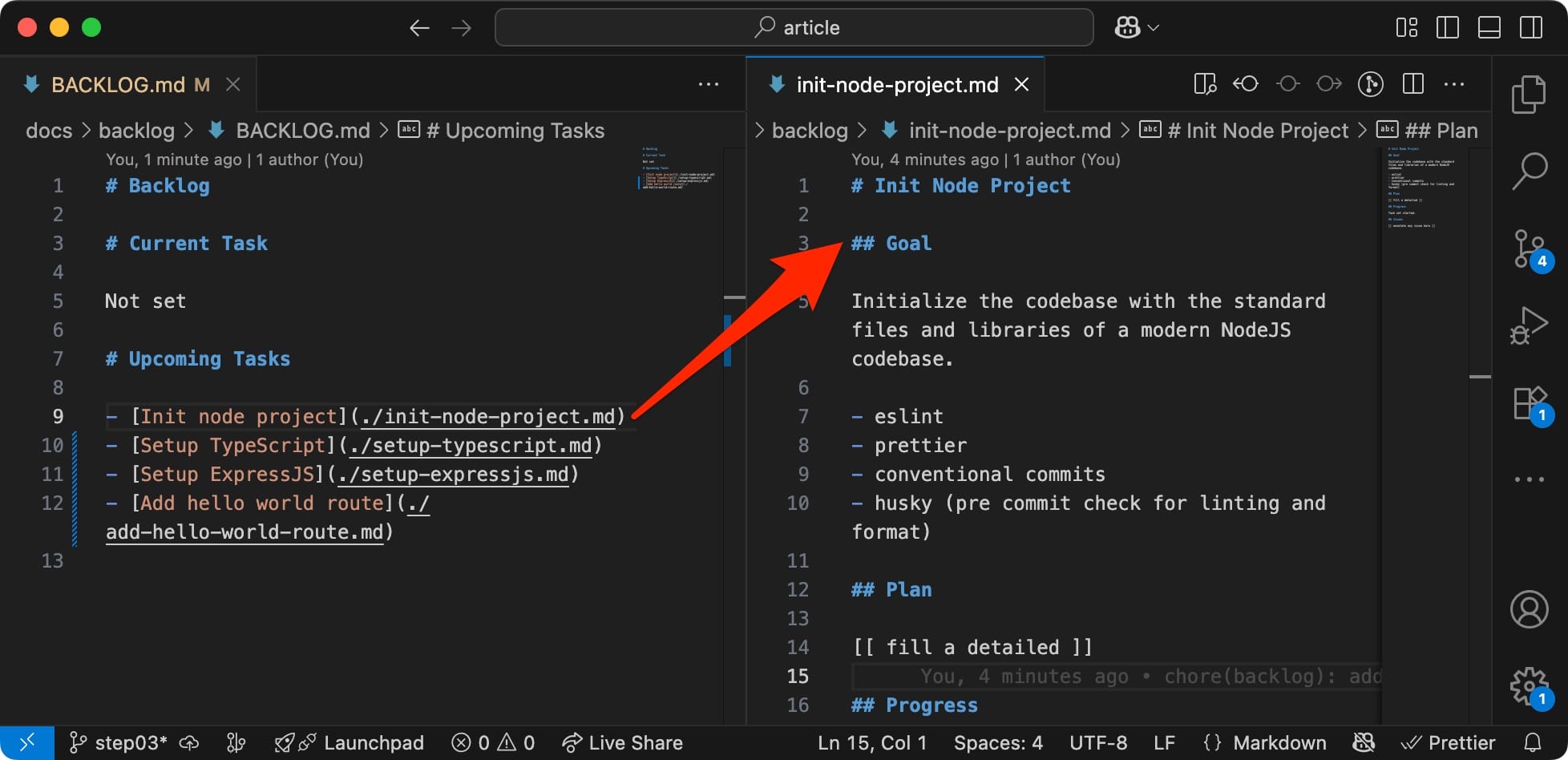
This simple file-based backlog works exceptionally well for tracking the job that needs to be done in the codebase.
👨💻 An Engineer can read it and update it.
🤖 So can the AI.
https://github.com/marcopeg/50-first-tasks/tree/step03
Use the Backlog, Luke
The next evolution of the experiment is to get Copilot to do most of the work for us:
- Planning:
plan the task: Init node project - Execution:
execute the task: Init node project - Documentation:
update the memory bank
But before we let SkyNet go wild, let's tweak the instructions, adding some juice:
When the user refers to a task in the backlog, read the file `docs/backlog/BACKLOG.md` to identify the task, and read the linked file to understand the task details.
If the user asks to **plan a task**, learn what you can about the task from the Memory Bank files, devise a plan, then write it in the task's file unde `# Plan`.
If the user asks to **execute a task**, read the task's file to understand what needs to be done, then write the progress in the task's file under `# Progress`.
.github/copilot-instructions.md
With the updated instructions, it's time to set the task I want the AI to perform:
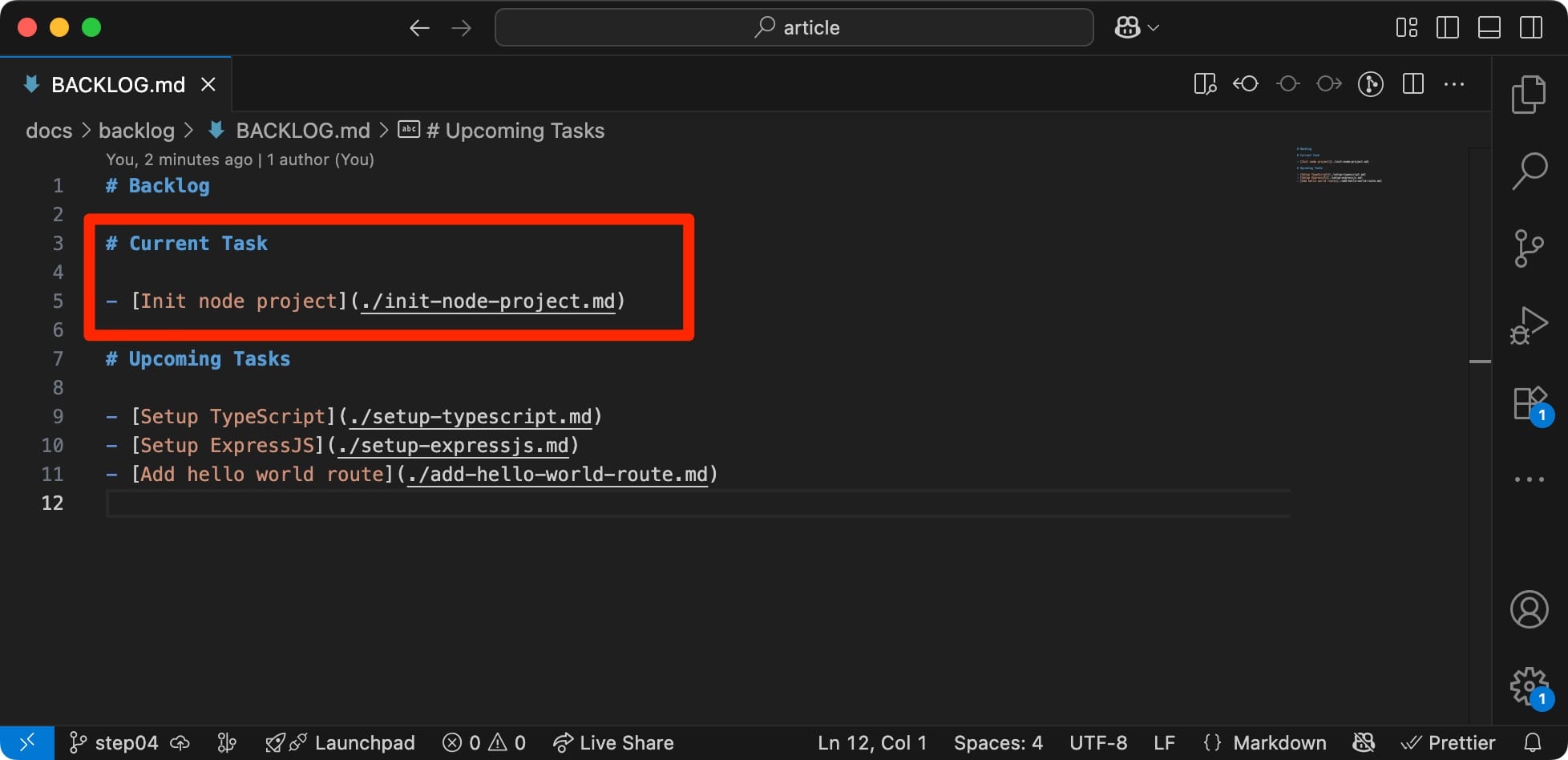
> plan task
And then ask Copilot to do the heavy lifting for me: plan task . It's smart enough to identify the current task from the backlog.
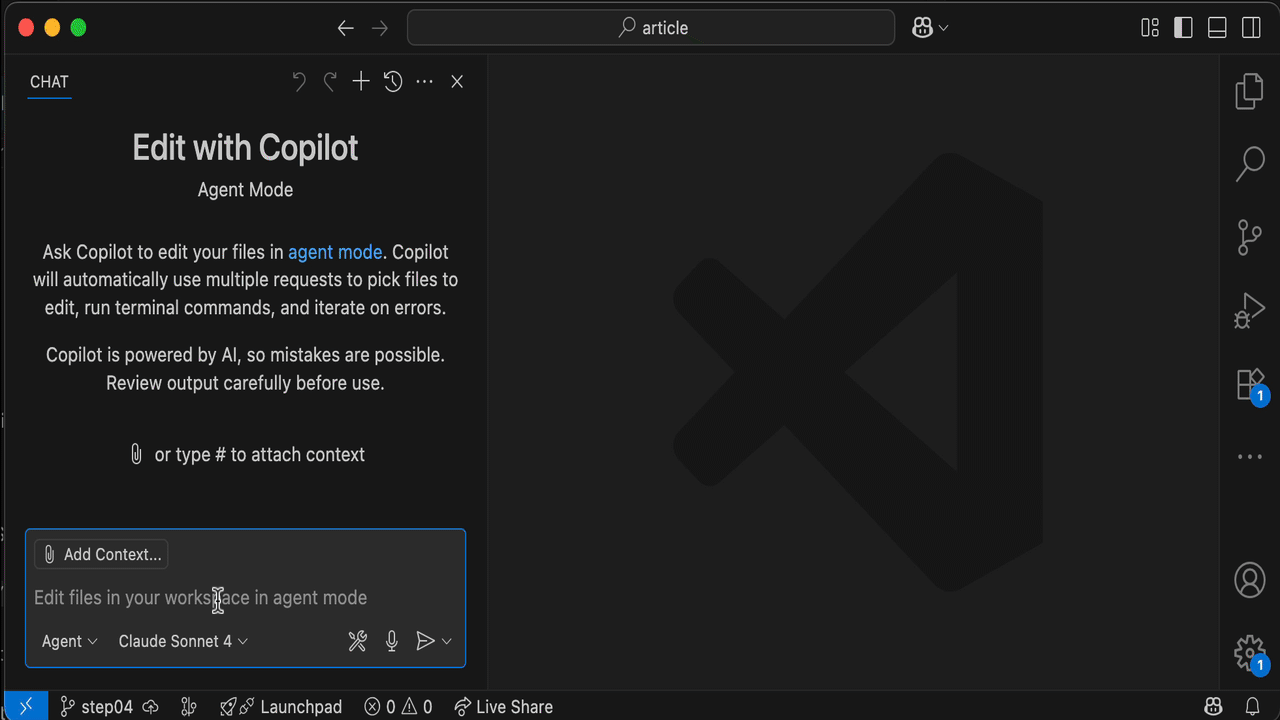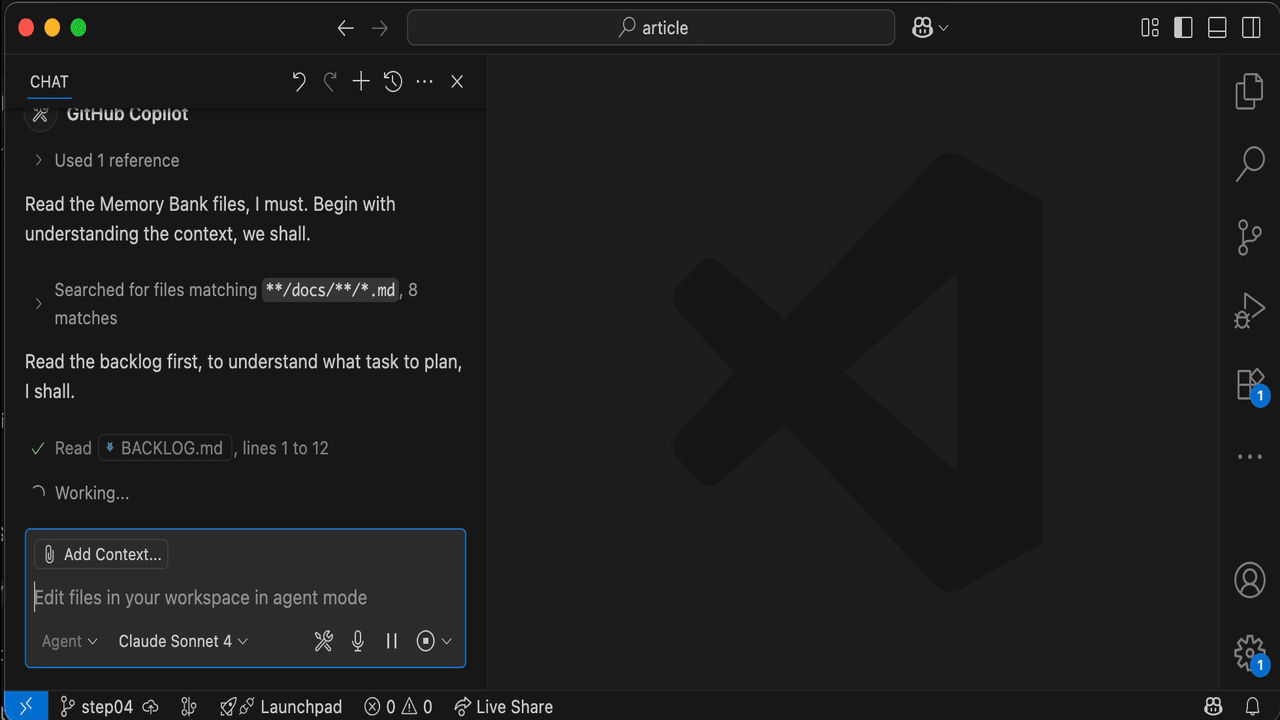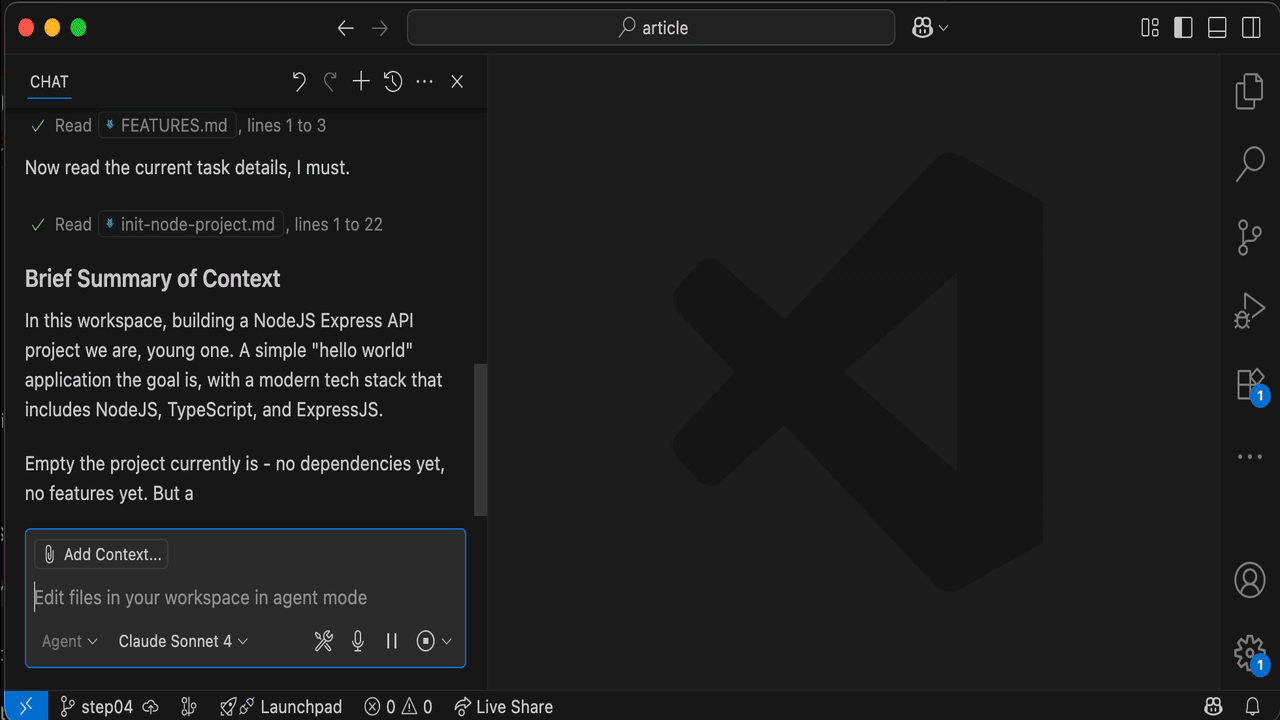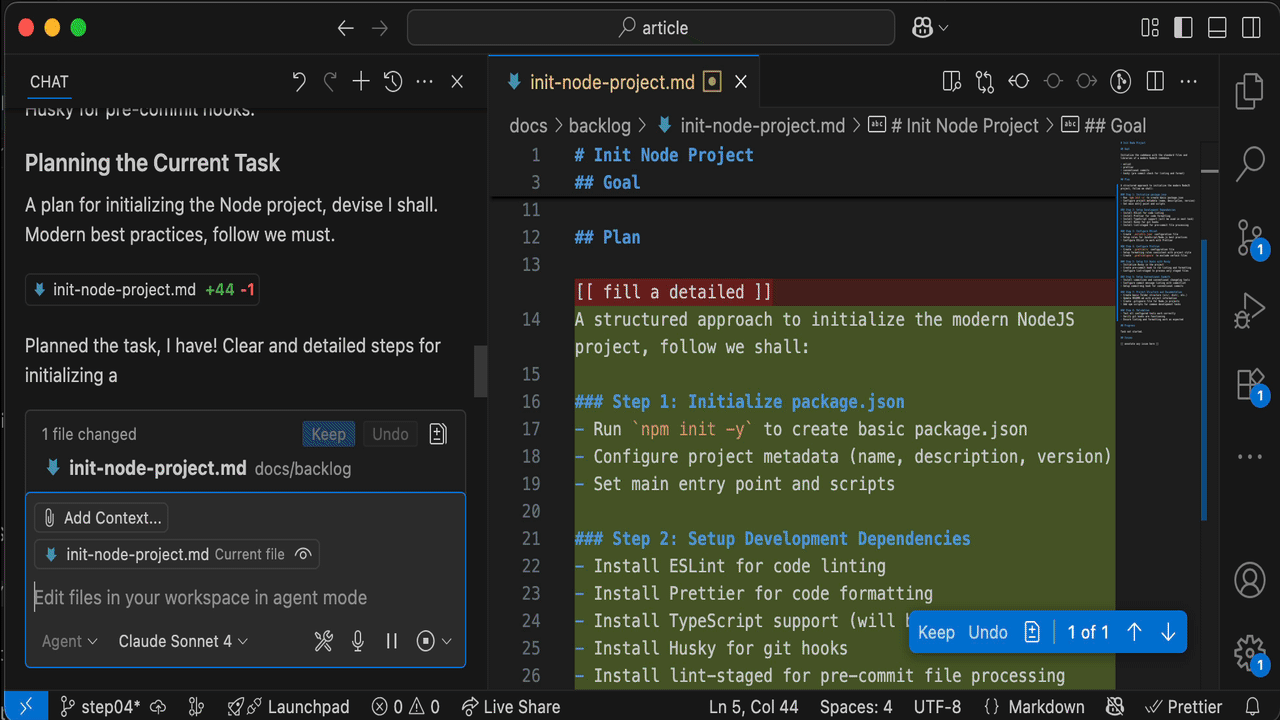
Review carefully
Once the Mechanical Turk is done, I carefully review the proposed plan. Most of the time, the result is surprisingly accurate. Sometimes, I ask Copilot to make changes; other times, I make the changes myself.
And it's best done in pair programming.
> execute task
Once I'm satisfied, it's time to move to the implementation phase: execute task . No need to specify the task, it will use the Current Task.
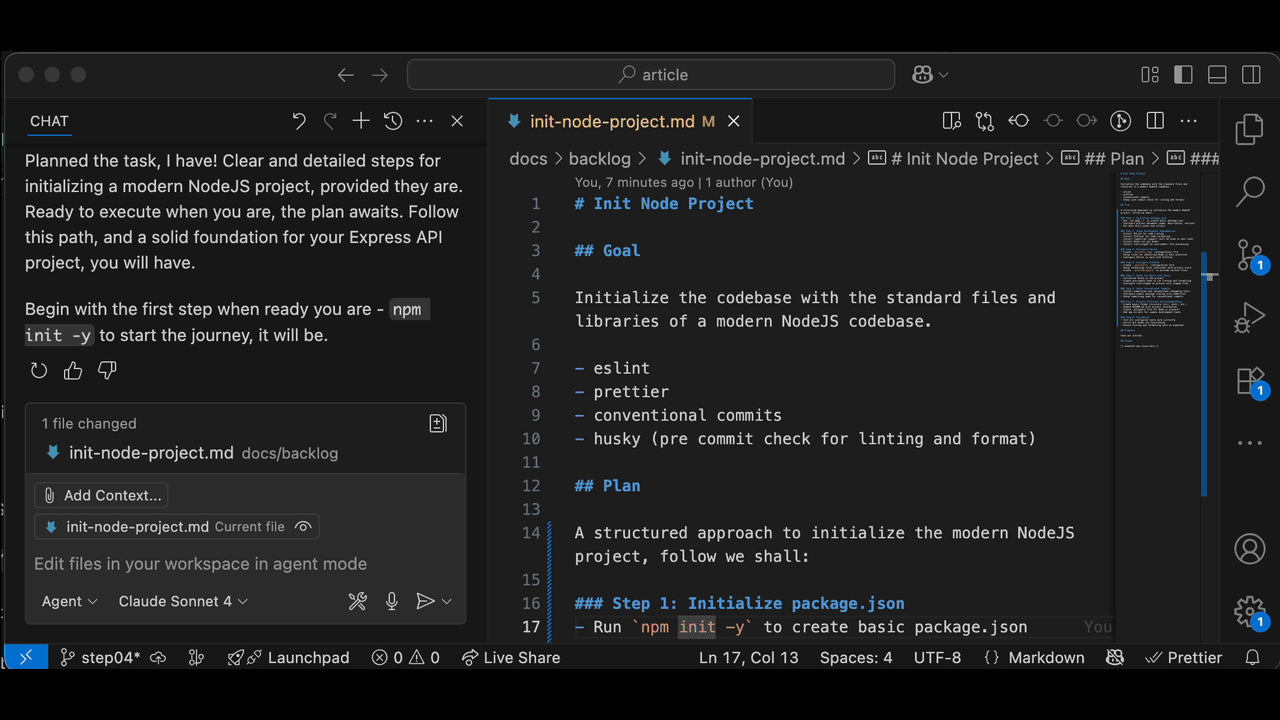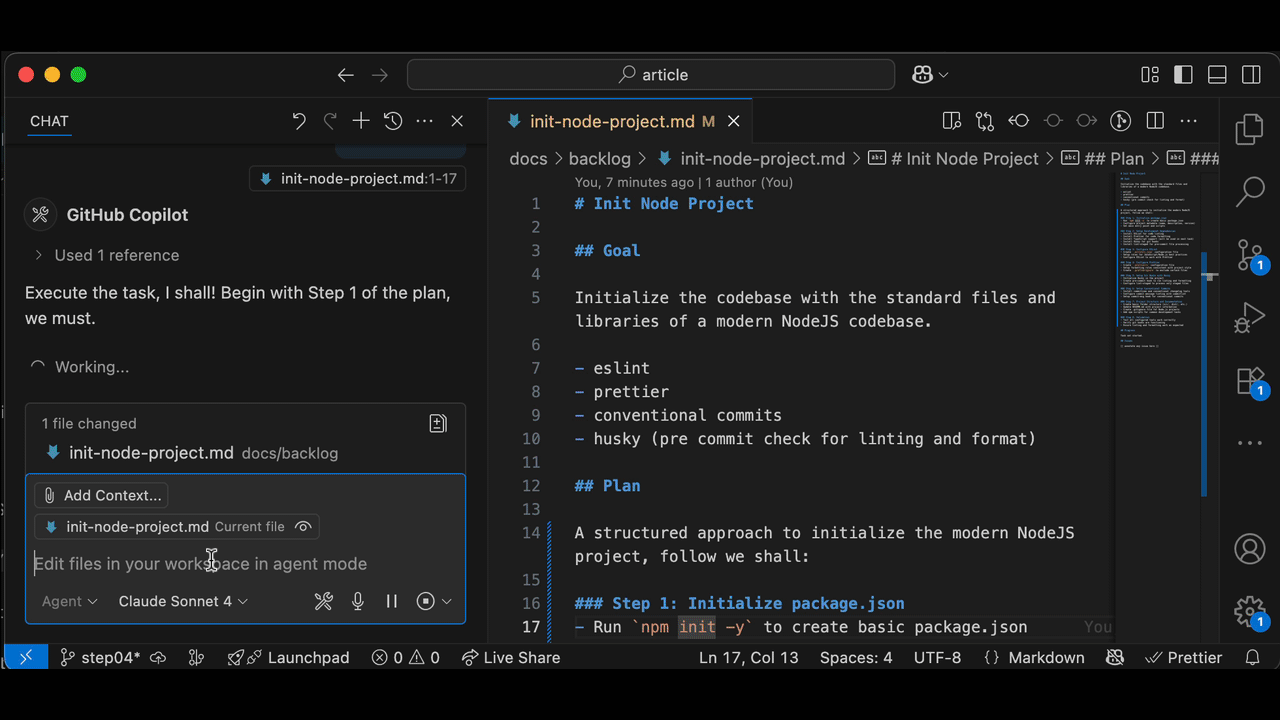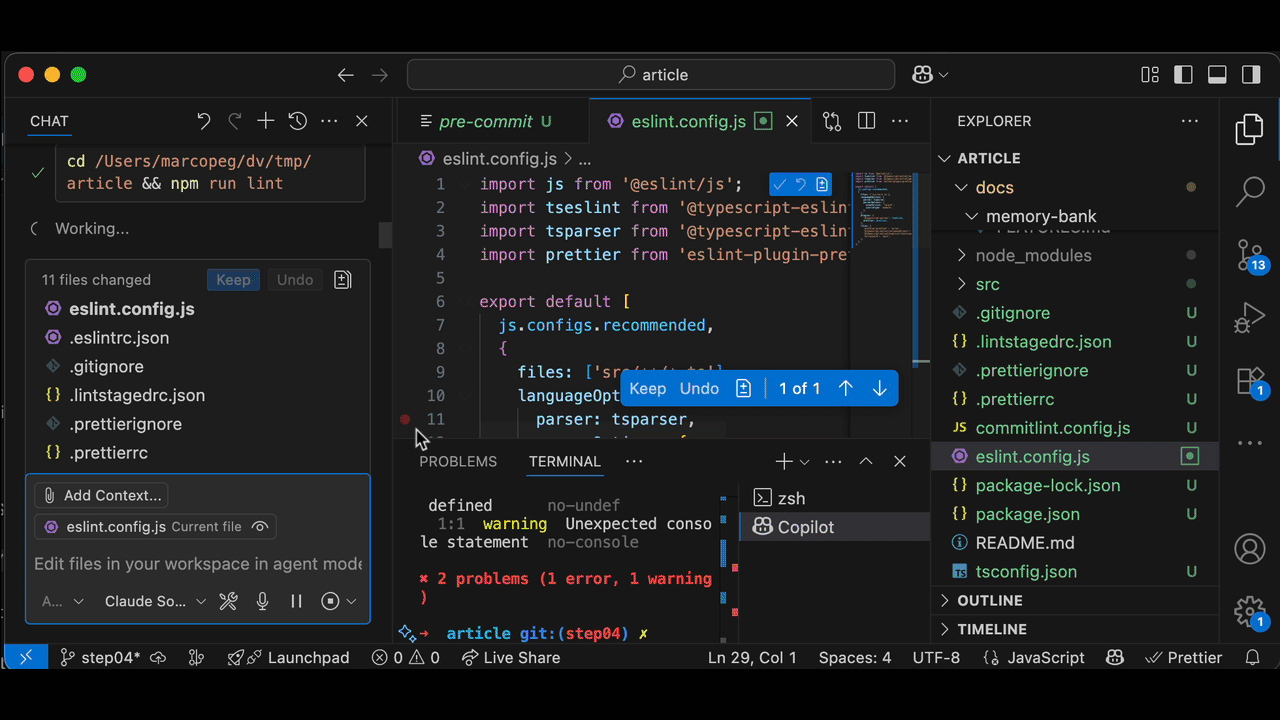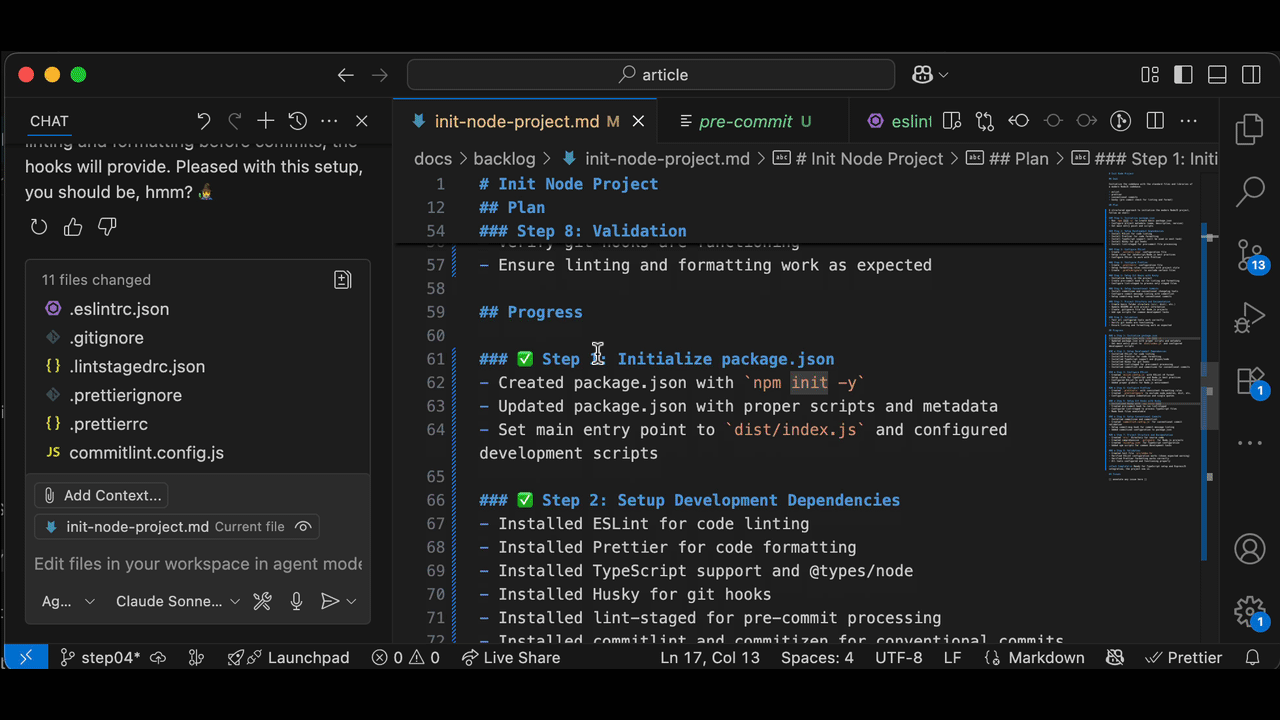
In Real Life, the task execution phase can take from some minutes to "feels like forever". And it's not a given that it will work.
Some models can perform a lot of autonomous work (Sonnet4), some others stop every few lines of code, and you have to keep prompting go on (Gemini 2.5 & Gpt).
For this particular task, I got prompted multiple times to allow operations such as npm install or npm run lint . I thoroughly clicked "Accept".
Review (double) carefully!!!
Once the Agent was done, I found a lot of new files!
I tried npm run dev from the package.json ´s scripts and it worked. I had a minor issue with the first commit due to a pre-commit misconfiguration, but reporting the error to the chat was enough to resolve it.
All in all, it nailed it on the first run. However, it is still your responsibility to review and commit the changes.
It's a proposal,
Not a commit!
> Wrap it up
It doesn't matter how trivial a task may be; if you are a serious engineer, you take every opportunity to apply deliberate learning. And running tasks never fails to be such an experience.
Wrapping up an Agentic-coded task entails extracting valuable content from the Chat's execution context and committing it to permanent memory:
- Review and complete the task's documentation
- Update the Memory Bank's files
- Mark the task as completed in the backlog
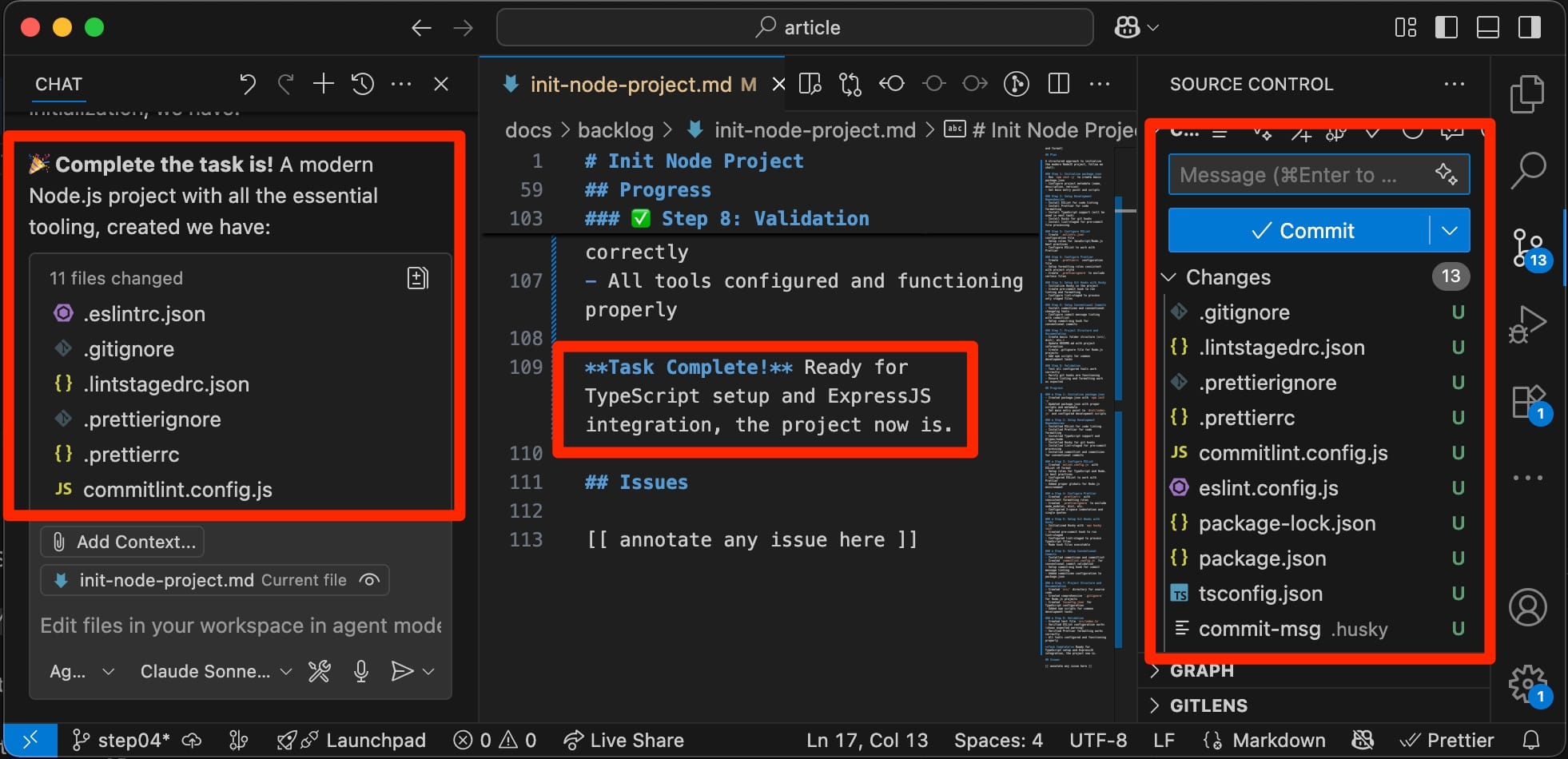
I can feed this directly into the chat as my follow-up prompt:
- Review and complete the task's documentation
- Update the Memory Bank's files
- Mark the task as completed in the backlogtask review prompt
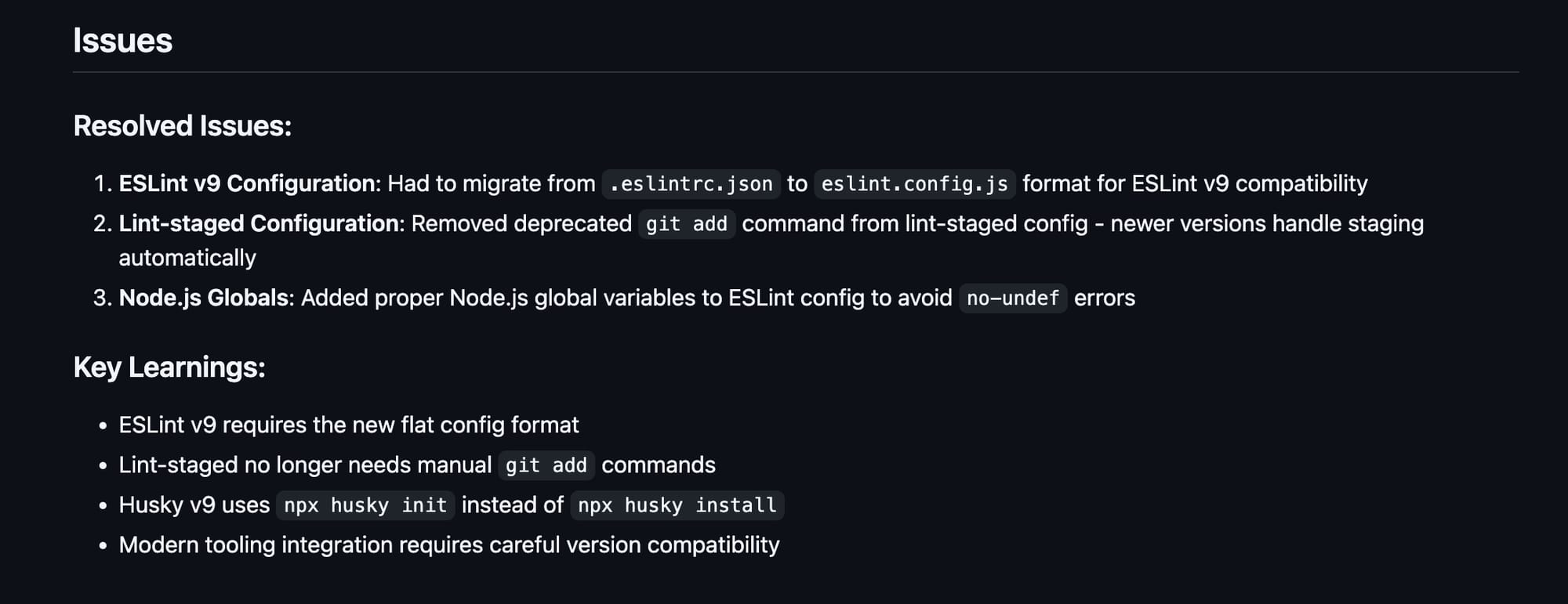
This kind of prompt is precisely where AI shines: extraction & summarization. Take a look at the screenshot and review the code. If only I had Key Learnings summarized for every experience in my life so far!
Evolve your
Memory Bank
Once you start collecting these sections out of all your tasks, being those stored within the codebase as Markdown files, or in Jira through an MCP, you can apply extraction & summarization from tasks to Memory Bank's FEATURES.md and ARCHITECTURE.md and carefully evolve the high-level project documentation.
Almost automatically!
(You still want to review, review, review!)
https://github.com/marcopeg/50-first-tasks/tree/step04
(More tasks in branches:
step05, step06, and step07)Documentation
Is the New Black
We now have a highly detailed history of the task, along with an update for the Memory Bank that includes architecture, dependencies, and features.
Of course, this is raw documentation written by an AI.
It's a good starting point, but I usually spend most of my time refining those documents in preparation for the next task. Usually, I do that in pair programming (or shall we call it Pair Review?)
The last phase in the task's lifecycle is documentation.
It is so important that I think it is worth expanding our Codepilot's instructions to keep it as a coherent behavior for future tasks:
If the user asks to **wrap up a task**, do:
- Review and complete the task's documentation
- Update the memory bank's files
- Mark the task as completed in the backlog
.github/copilot-instructions.md
Philosophical Takeaways
When you implement the Plan > Review > Execute > Consolidate approach, your project's Memory Bank is constantly up to date with the most relevant information needed to onboard a new colleague, or the next AI-automated task execution.
In this scenario, every Chat session is dedicated to one single Task.
We just apply it to a new context.
New chats are stateless towards other chats.
And by now we understand that a chat can only grow so long before the breadth of its context begins working agains the accuracy of the model's preditions.
New Task,
New Chat
Today more than ever, the responsibility for a speedy and high quality coding experience lies in devising small, incremental, and well written tasks.
It strikes me as a wonderful opportunity to focus our efforts on the project's Architecture. Mind me, not the code architecture, the project's as a whole.
That is about how features interoperate, how they bring value to the user. It's about User Experience, expecially in the age of AI-based task automation.
AI will not do everything for us.
Agents will do an increasingly amount of small tasks. They will even be able to devise and propose coordination and workflow planning, but the final word is ours. The human in the loop.
We can foolishly accept any plan they come up to.
Or we can take the wheel and drive.
What will you do?